온큐의 DR
DR 목적으로 사용할 온큐를 보호대상서버들과 떨어진 원격지에 설치하는것으로 DR 준비가 완료됩니다.
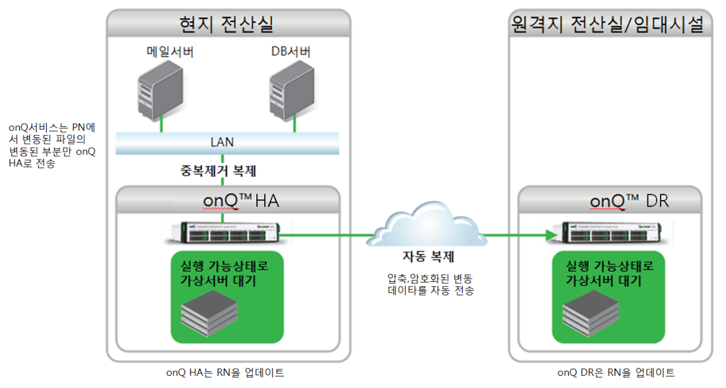
온큐 HA 장비와 온큐 DR 장비는 자동으로 업데이트를 수행하고 서로의 상태를 동기화시켜둡니다.
HA사이트에서 서비스가 원활하지 못하게되면 온큐는 관리자에게 통보를 합니다.
정보시스템들의 상황을 가장 잘 아는 관리자의 판단에 따라 DR용 온큐에서 준비해둔 해당 서버들의 가상머신을 클릭해서 켜기만 하면 수 분 안에 서비스를 정상화시킵니다. 서비스 사용자들은 현지 전산실의 재난 상황에서도 서비스가 온큐에서 이루어지고 있는지를 알 수도 알 필요도 없을 것입니다.
따져보십시오.
● 서버 장애가 생기면 얼마 만에 온큐로 서비스를 복구할 수 있는가?
– 수 분 안에(보호하던 서버 상황에 따라 다릅니다만, 경험적으로 5분 내외) 이루어집니다.
● HA용 온큐와 DR용 온큐 사이의 통신은 안전한가?
– DR과 관련한 공인보안규정들(PCI, HIPAA, SOX, FDIC, CUNA)을 준수합니다.
● HA용 온큐가 설치된 곳과 DR용 온큐가 설치된 곳 사이를 서로 양방향 DR이 가능한가?
– 가능합니다. 서로 떨어진 곳에 각각 한 대 씩의 온큐를 설치하고 두 지역 서버들에 대해 HA와 DR을 모두 구현할 수 있습니다.

● 서버가 설치된 곳이 여러 곳일 때 한 대의 온큐로 DR이 가능한가?
– 가능합니다. 보호대상 서버들이 설치된 곳이 여러 지역이라도 온큐 한 대로 간편하게 각 지역의 서버와 온큐에 대해서 DR을 구성할 수 있습니다.